"Damn, that rock is heavy."
-- Grrrg, son of Booog, discoverer of The Big Data Problem
Big Data is big business, and all the nerds are talking about it. Since many of my readers are not nerds (and I mean that in the nicest way), I'd like to break down what Big Data is, and then I'd like to put it in a historical context that I think has been somewhat neglected.
People and devices are more connected than ever before. Fortunately for you, you represent only one of those people, and you have only a handful of devices and a few friends. All of your data, and all of the relevant data from the people you care about, fits in less than a cubic foot on your desk. If you search for a particular piece of information stored there, your computer can find it in a couple of seconds. Congratulations; you're doing fine: you don't have a Big Data Problem.
Your ISP has tens of thousands of customers just like you. LinkedIn had 100 million members as of a year ago. Facebook has almost 900 million members. And They. Save. Everything. In other words, they have 5-10 orders of magnitude more data than you do. That's far too much to store in one place, and if they searched their data the way you search yours, your one-second search would take them a week. If you typed a query into Google.com and had to wait a week for your search results to come back, you'd be pissed -- like, really pissed.
That, my friends, is a Big Data Problem.
The History of Big Data -- 10,000 BC to the Present
In order to do something useful with a collection of information, you need several things:
- The information comes from all over; first, you need to get it most of the way from its source to its destination.
- You need to get it the rest of the way to its destination -- the so-called "last mile".
- You need to store it somewhere -- or possibly several somewheres.
- You need to get the stored information and the means to process it to the same place at the same time.
OK, that's a fairly bogus example. Let's look at the actual costs of data transport and storage over the last few decades. All of the following costs are falling at a rate of just over one order of magnitude every five years:
1. The cost of Internet backbone transport
 |
| Image credit: Ciena Insights |
2. The cost per transistor per clock cycle
| Image credit: Singularity.com |
3. The cost of storage
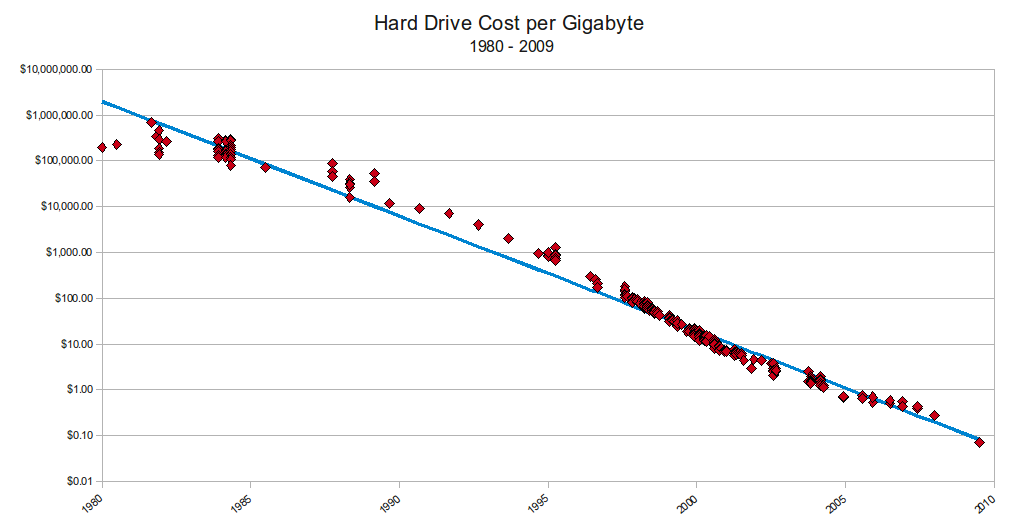 |
| Image credit: Matt Komorowski |
In contrast, the cost per unit of processing power is falling by three orders of magnitude every five years.
 |
| Image credit: me, based on above-linked Wikipedia data |
Meanwhile, local-area network transport is improving by only half an order of magnitude every five years. (10 Mb/s Ethernet was cutting edge in 1981; in 2012, the cutting edge is 10 Gb/s Ethernet.)
What Do We Do About It?
All of the above data can be summarized very simply:
More transistors for less money means that a broader class of devices -- not just "computers" but also phones and cars and pacemakers -- can be made smarter and more network-capable. Cheaper wide-area network connectivity means that you can get all of their data to you. Cheaper storage means you have a place to put it once it arrives. All of these things are improving roughly in sync with each other.
Here's the important But: once the data gets onto your local network, it hits a wall. Short-haul networks are called upon to handle the aggregate of all of these incoming feeds -- multiply the improvements in bandwidth-per-link by the increase in the number of links. But they're actually improving at a slower rate than either of those input factors, much less the multiple of those factors. Result: bottleneck, big time.
How do we work around this bottleneck? How do we leverage a less-expensive resource to solve an expensive problem? We throw CPU cycles at it, of course! Processing power is getting cheaper even faster than the factors above. Therefore, we move the (smaller) computation to the (bigger) data instead of the other way around, and we parallelize that computation so that we can take advantage of all of those dirt-cheap processors we've got lying around.
We've Been Here Before
At the macro level, these trends are not new, nor is the approach to solving them. A colleague recently shared with me his experience of dealing with "huge" data sets 30 years ago. Memory was measured in kilobytes back then, and networks in kilobits per second. Consequently, data sets many megabytes in size were much too large to move around, and they were much too large to load into memory to operate on. The approach? The data was collected in clusters of powerful machines called "data centers". Less-powerful "clients" would dispatch jobs to them, and the machines in the data centers would break the data set into small chunks and run these jobs against them, one chunk at a time. Finally, they would merge these intermediate results into a final result and return it to the clients. Sound familiar? Sounds like cloud computing and MapReduce to me.
In future posts, I'll talk more about what is different this time around, what it means for you and me, and how we should think about approaching these recurring challenges. Stay tuned.
No comments:
Post a Comment